本文最后更新于 2026-02-02T02:03:22+08:00
题目来源与furryctf2025,这题首先要恢复MZ头,然后查看文件类型,发现是用Nuitka打包的,学习的文章:https://www.52pojie.cn/thread-2063208-1-1.html
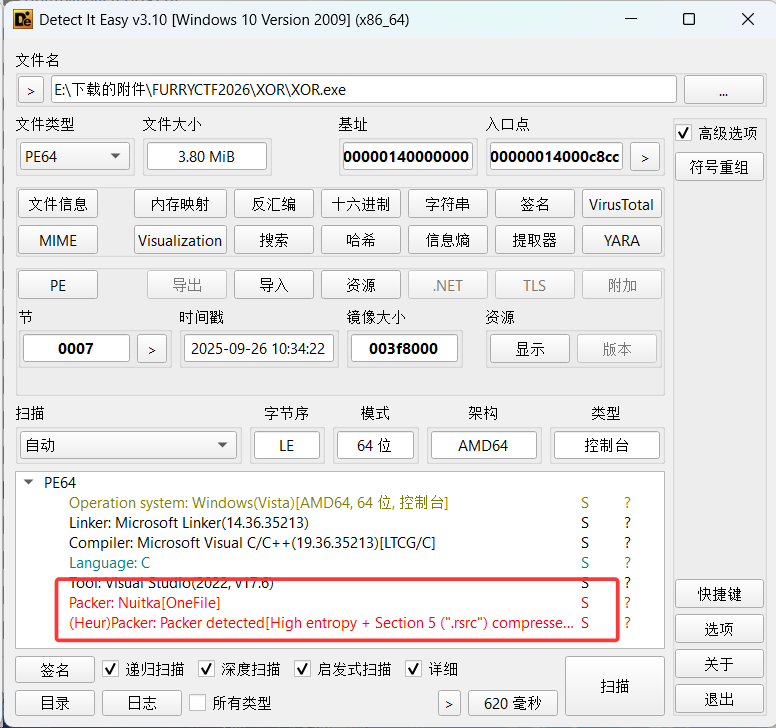
从这里下载https://github.com/extremecoders-re/nuitka-extractor库nuitka-extractor提取内置的二进制文件
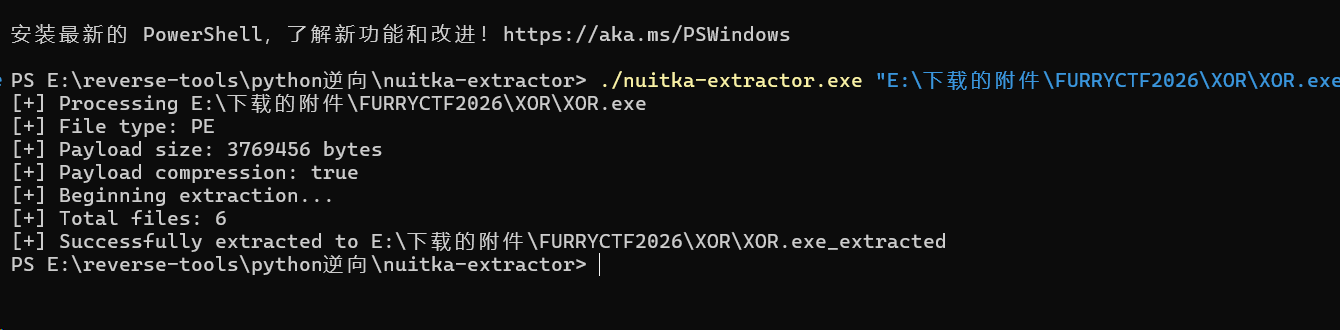
这里得到的是script.dll文件,拖入ida分析
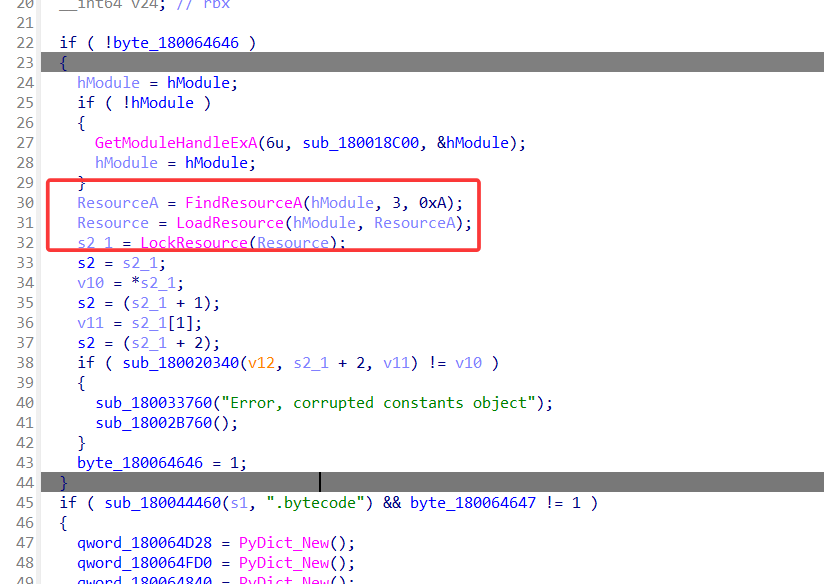
这个函数的作用是从 PE 资源中加载“常量 + 字节码表”,校验,根据模块名定位一段字节码,逐条解析生成 Python 对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
| unsigned __int8 *__fastcall sub_180022180(__int64 a1, _QWORD *AttrString, const char *s1)
{
HMODULE hModule;
HRSRC ResourceA;
HGLOBAL Resource;
int *s2_1;
int v10;
__int64 v11;
__int64 v12;
const char *s2;
const char *s1_1;
int v15;
int v16;
__int64 v17;
int v18;
const char *v19;
int v20;
__int64 v21;
unsigned __int8 *result;
__int64 v24;
if ( !byte_180064646 )
{
hModule = hModule;
if ( !hModule )
{
GetModuleHandleExA(6u, sub_180018C00, &hModule);
hModule = hModule;
}
ResourceA = FindResourceA(hModule, 3, 0xA);
Resource = LoadResource(hModule, ResourceA);
s2_1 = LockResource(Resource);
s2 = s2_1;
v10 = *s2_1;
s2 = (s2_1 + 1);
v11 = s2_1[1];
s2 = (s2_1 + 2);
if ( sub_180020340(v12, s2_1 + 2, v11) != v10 )
{
sub_180033760("Error, corrupted constants object");
sub_18002B760();
}
byte_180064646 = 1;
}
if ( sub_180044460(s1, ".bytecode") && byte_180064647 != 1 )
{
qword_180064D28 = PyDict_New();
qword_180064FD0 = PyDict_New();
qword_180064840 = PyDict_New();
qword_180064788 = PyDict_New();
qword_180065048 = PyDict_New();
qword_1800648B8 = PyDict_New();
qword_180064FD8 = PyDict_New();
qword_180064FF0 = PyDict_New();
byte_180064647 = 1;
}
s2 = s2;
s1_1 = s1;
do
{
v15 = s1_1[s2 - s1];
v16 = *s1_1 - v15;
if ( v16 )
break;
++s1_1;
}
while ( v15 );
v17 = -1LL;
do
++v17;
while ( *(s2 + v17) );
v18 = *(v17 + s2 + 1);
v19 = (v17 + s2 + 5);
if ( v16 )
{
do
{
s2 = &v19[v18];
v20 = strcmp(s1, s2);
v21 = -1LL;
while ( s2[++v21] != 0 )
;
v18 = *&s2[v21 + 1];
v19 = &s2[v21 + 5];
}
while ( v20 );
}
result = (v19 + 2);
if ( *v19 )
{
v24 = *v19;
do
{
result = sub_180021050(a1, AttrString++, result, s2);
--v24;
}
while ( v24 );
}
return result;
}
|
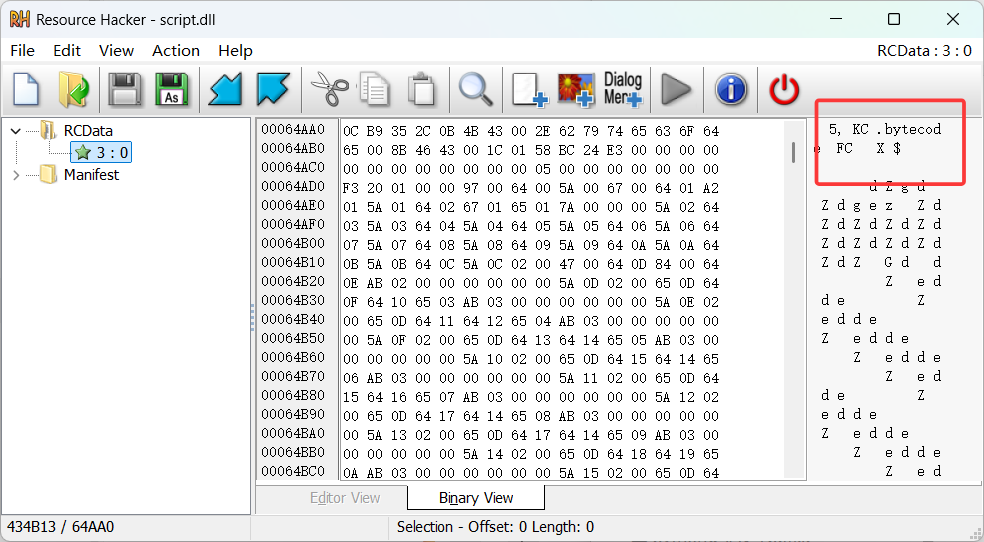
Resource ID = 3,Type = 0xA(RT_RCDATA)
工具:ResourceHacker,利用这个工具可以提取字节码
导出之后的任务就是分析字节码了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import io
import struct
def read_uint32(bio):
return struct.unpack("<I", bio.read(4))[0]
def read_uint16(bio):
return struct.unpack("<H", bio.read(2))[0]
def read_utf8(bio):
bs = b""
while True:
bs += bio.read(1)
if b"\x00" in bs:
break
return bs[:-1].decode("utf-8")
def main():
with open("script.bin", "rb") as f_in:
bs = f_in.read()
bio = io.BytesIO(bs)
hash_ = read_uint32(bio)
size = read_uint32(bio)
print(f"hash: {hex(hash_)}")
print(f"size: {hex(size)}")
while bio.tell() < size:
blob_name = read_utf8(bio)
blob_size = read_uint32(bio)
blob_count = read_uint16(bio)
print(f"name: {blob_name}, size: {hex(blob_size)}, count: {hex(blob_count)}")
bio.seek(bio.tell() + (blob_size - 2))
if __name__ == "__main__":
main()
|
通过这个脚本打印出字节码文件的模块目录,如下图,发现了关键的main目录
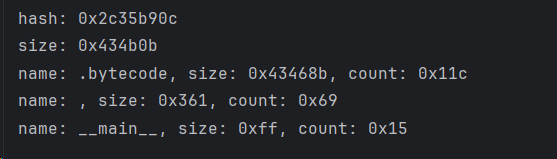
接下来就是要分析出这个main函数的内容了,不过不同版本的nuitka的解析方式也不同,于是需要在通过分析解出来的strict.dll文件找出解析函数
可以通过搜索字符串blob确定解析函数的位置sub_180021050
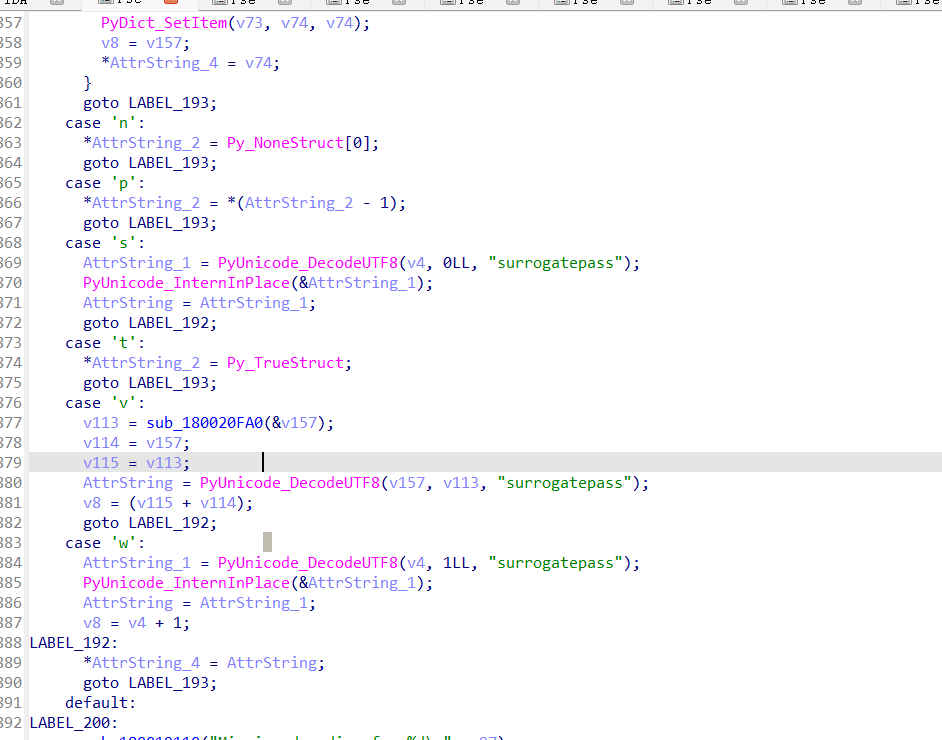
然后根据这个解析函数确定python脚本来解析main函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
| import io
import struct
def read_u8(b): return struct.unpack("<B", b.read(1))[0]
def read_u32(b): return struct.unpack("<I", b.read(4))[0]
def read_varint(b):
shift = 0
r = 0
while True:
c = read_u8(b)
r |= (c & 0x7F) << shift
if c < 0x80:
return r
shift += 7
def read_cstring(b):
s = b""
while True:
c = b.read(1)
if not c or c == b"\x00":
break
s += c
return s
def decode(b):
t = chr(read_u8(b))
if t == ".":
return None
if t in ("a", "u"):
s = read_cstring(b)
return s.decode("utf-8", "ignore")
if t == "w":
return b.read(1).decode("utf-8", "ignore")
if t == "s":
return read_cstring(b).decode("utf-8", "ignore")
if t == "v":
n = read_varint(b)
return b.read(n).decode("utf-8", "ignore")
if t == "b":
n = read_varint(b)
return b.read(n)
if t == "c":
return read_cstring(b)
if t in ("l", "q"):
v = read_varint(b)
return v if t == "l" else -v
if t in ("t", "F", "n"):
return {
"t": True,
"F": False,
"n": None
}[t]
if t == "T":
n = read_varint(b)
return tuple(decode(b) for _ in range(n))
if t == "L":
n = read_varint(b)
return [decode(b) for _ in range(n)]
if t == "D":
n = read_varint(b)
d = {}
for _ in range(n):
k = decode(b)
v = decode(b)
d[k] = v
return d
if t in ("P", "S"):
n = read_varint(b)
items = [decode(b) for _ in range(n)]
return set(items) if t == "P" else frozenset(items)
raise ValueError(f"Unhandled type {t!r}")
def main():
with open("script.bin", "rb") as f:
data = f.read()
b = io.BytesIO(data)
magic = read_u32(b)
size = read_u32(b)
print(f"magic={hex(magic)} size={size}")
while b.tell() < size:
name = read_cstring(b).decode()
blob_size = read_u32(b)
count = struct.unpack("<H", b.read(2))[0]
print(f"[+] blob {name} count={count}")
if name == "__main__":
for i in range(count):
obj = decode(b)
print(f"{i}: {obj}")
break
else:
b.seek(b.tell() + blob_size - 2)
if __name__ == "__main__":
main()
|
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| magic=0x2c35b90c size=4410123
[+] blob .bytecode count=284
[+] blob count=105
[+] blob __main__ count=21
0: Enter flag:
1: aenc_flag
2: print
3: ('Success!',)
4: ('Wrong!',)
5: key
6: <genexpr>
7: check.<locals>.<genexpr>
8: check
9: __doc__
10: __file__
11: __cached__
12: __annotations__
13: [122, 101, 108, 122, 81, 88, 25, 92, 25, 88, 89, 27, 68, 77, 117, 27, 89, 117, 76, 95, 68, 11, 87]
14: 42
15: main
16: script.py
17: ('.0', 'b')
18: <module>
19: ('_input', 'flag')
20: None
|
有一点小问题,不过已经可以分析出来了,就是将给出的密文进行xor,key是42,得到flag:POFP{r3v3rs1ng_1s_fun!}